Recent advances in AI has contributed to the rebirth of a chatbot-type dialogue system being able to interact with people through natural language communication. This could help people better understand the world around them and communicate more effectively with others, effectively bridging communication gaps. Therefore, it is important to understand the quality attributes associated developing and implementing high-quality conversational agents and diaglouge system.
Muse is a NLP engine developed by AKA Intelligence, with a focus on natural conversation. Engineers at AKA and Softbank are collaborating to bring the Muse engine into Pepper, Softbank’s humannoid robot, to use Muse as Pepper’s English conversation system. Muse is also expanding into other hardware platforms as well. A typical example is Musio, a social robot for educational purposes. It presents specific topics to the students in the form of voices, texts, images, faces or a combination of these
The performance and utility of Muse dialogue system have indirectly been substantiated by the market response, but there is little objective information to evaluate the performance of the dialogue engine in comparison to other production dialogue systems. The purpose of this article is to provide an objective evaluation of the engine’s dialogue performance by comparing three main factors of dialogue systems. Our analysis is performed on tens of thousands of real human-chatbot dialogs from Loebner Prize competition.
Evaluation Method
We used evaluation methods of Loebner Prize competition to measure the conversation quality of Muse engine and provide a comprehensive review for the quality attributes. The Loebner Prize, which was an attempt to implement the Turing test, is an international contest run by the AISB (The Society for the Study of Artificial Intelligence and the Simulation of Behaviour) where chatbots compete with each other to find the most humanlike. Mitsuku has won the annual Loebner Prize competition for the most humanlike bot four times, so we evaluated Muse’s performance against Mitsuku. We adopted three evaluation metrics to measure:
Table 1: Factors to measure the performance of dialogue systems
1. Naturalness
Evaluating naturalness is how well a dialogue system can maintain a natural conversation flow. However, evaluation of maintaining naturalness in a conversation suffers from the problems of subjectivity. While human’s assessment system did not identify a concrete baseline for universal naturalness, we substituted naturalness evaluation as readability test by comparing Mitsuku with Muse’s engine. The readability test is calculated by Flesch reading-ease score to measure how easy a given text is to read. That is, text with a high Flesch reading-ease score is straightforward and easy to read. Normally, a reading-ease score of 60-70 is considered acceptable.
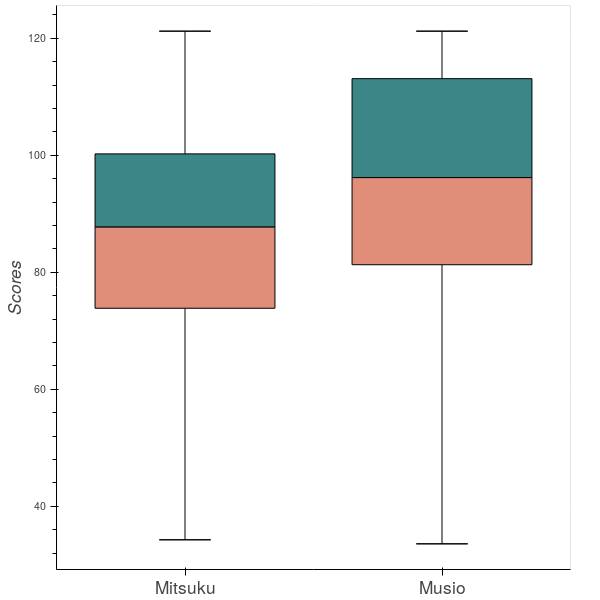
The below shows the Flesch reading-ease score of Mitsuku vs. Muse when each system analyzed general dialogue questions including 70 specific topics. This dialogue dataset comes from actual engines and contains 922 observations of response. The below result demonstrates that Musio with an average score of 94, is easier to understand than those of Mitsuku. Of course, the readability score will depend on the intended audience and on the content that dialogue system is delivering. For example, if the system is providing information geared toward elementary school children, it will want to keep the content at a lower level of sentence. In this sense, Musio is suitable for the target who is planning to learn foreign languages, but it is limited to accomodate to user’s changing demands.Musio is also recongnizing this issue and keeps trying to provide more advanced and customized contents for their target users.
Table 2 : Readability score & level
Figure 1: Flesch Reading-ease score
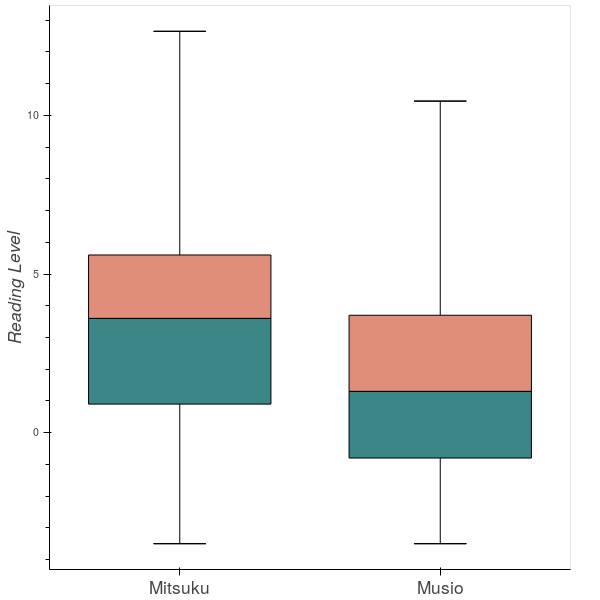
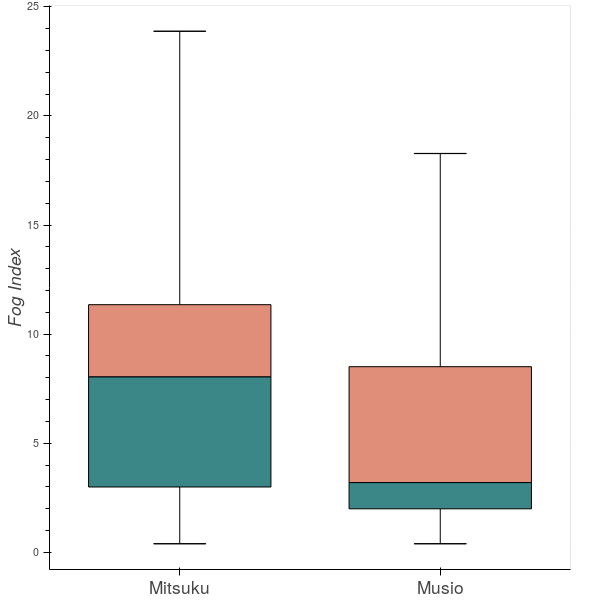
Both of Flesch-Kincaid grade level and Gunning for index are also well-known text readability measure. Flesch-Kincaid formula considers the number of syllables, words, and sentences for readability assessment, while Gunning for index is to calculate by counting the number of complex words in the text. From figure 2, we can see that the median value of Musio is smaller than Mitsuku’s. In both of the tests, lower numbers indicate material that is eaiser to read, so it shows the same result that Musio produces easier texts than Mitsuku.
Figure 2: Flesch-Kincaid grade level
Figure 3: Gunning fog index
2. Scope
Second is a range of topics that the dialogue system covers. Conversational success is not well defined by the length/time of human-chatbot’s dialogues. A conversation could be viewed as an exchange of information and opinions on a flow of topics, so the system is necessary to satisfy users by understanding the conversation topics and is possible to be related to how engaging and enjoyable was the conversation. Specifically, we examined a) topic scope – the ability of the system to converse on a variety of specific topics without repeating itself, and b) topic depth – the ability to sustain long and coherent conversations on a given topic.
The figure 3 shows that Musio’s engine has superior domain coverage in most of topics. We extracted 34 different topics from general conversation dataset, and then the engine’s responses are scored by human evaluators. The scope evaluation is to estimate how flexible the system can react when it faced domain-specific questions in a conversation, and the depth evaluation was supposed to capture how good the conversation was in terms of coverage of a suggested topic. From figure 3, we can see that the scores of topic scope and topic depth are better in Musio.
We could imagine that human evaluator ratings collected for each conversation are very noisy and have high standard deviation within each topic. Also, topic-level evaluation can sometimes be inaccurate and conducted separately when compared with the evaluation of shorter dialogues. In this sense, we are planning to objectively evaluate conversational topic depths with metrics such as response error rate and the coefficient of variation. As a future research, it is possible to estimate the topic depth with objective metrics and suggest the new features in order to broaden topic domain coverage of the dialogue engine.
Figure 4: Mitsuku vs. Musio: Topic domain coverage
3. Politeness
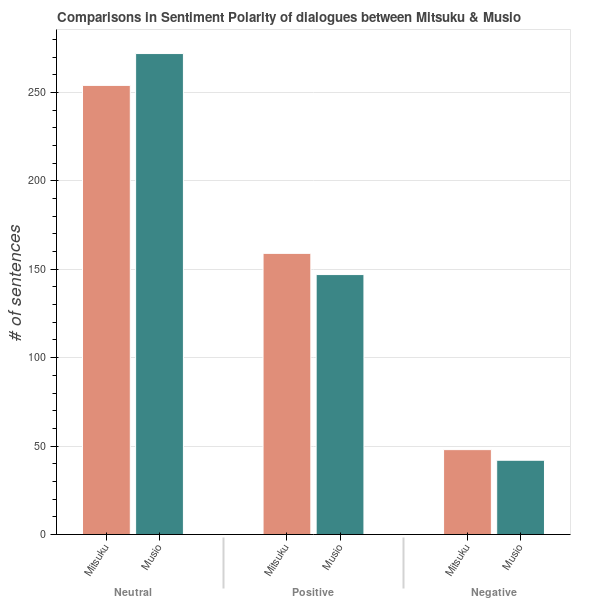
Muse engine is polite to users. No one wants to communicate with an impolite person, so Muse engine is continuously pursuing good manners and etiquette. That is, Muse engine contains concepts like socially desirable conversation. The below figure shows the result of sentiment analysis classifying the polarity of Musio’s answers in general conversation dataset. This indicates that Musio has tried to adopt neutral and positive attitudes towards users in the diagloue. AKA researchers continuously endeavor to design Musio’s personality that is based on the people who are going to interact with it. (This chart is analyzed by TextBlob, a library for processing textual data and assigning polarity score based on English movie reviews, Pang Lee polarity dataset v2.0)
Figure 5: Mitsuku vs. Musio: Politeness
Conclusion
In this article, two important goals were achieved namely: a) the performance of Musio was gathered using objective evaluation methods by comparing the dialogues generated from Misuku, four-time winner of Loebner prize competition, and b) the results proposed meaningful guidance for designing the pipeline of a natural, robust and kind dialogue system. Although the performance was reasonably good, improving robust conversational engine has remained largely unsolved. Also, Musio’s ultimate challenge is to build a social chatbot which can converse coherently and engagingly on popular topics and current events with humans. If chatbot is meant to be adapted to provide a specific service for users, Musio still has a long way to go before it becomes fully perfect. At the next article, we will address how Muse’s engine is built to improve grammaticality, and evaluate the performance of linguistic accuracy. AKA’s quest for a perfect conversational engine continues.