- Control the “difficulty” of responses
- Adjusting the level of Musio’s responses to suit the user’s level of English, following the Common European Framework of Reference for Languages guideline – the proficiency of the speaker is categorized into one of A1, A2, B1, B2, C1, and C2: A1 being the most elementary and C2 being the most advanced.
- The level of Musio’s responses can be determined by the user (needs work on frontend / Musio OS), or be automatically determined by analysing the level of the user’s English.
- in Easy Mode, the level of Musio’s responses are determined at the utterance level. Musio’s response will not exceed a given user’s level. Examples:
- Specified level: A1
- u: how are you
- m: [A1] I’m fine. How are you ?.
- u: i am doing well, thanks
- m: [A1] I’m a little tired, but otherwise fine.
- u: why are you tired
- m: [A1] I have not been able to sleep well
- u: do you watch tv until late
- m: [A1] Yes, and sometimes the TV watches me while I sleep.
- u: what do you watch on tv
- m: [A1] I love watching adventure movies !.
- u: i like dramas
- m: [A1] I have never watched any musical movie before.
- u: i don’t like musical movies
- m: [A1] Me, too. I think they are lame
- Specified level: B1
- u: hi
- m: [A1] Good morning.
- u: how are you
- m: [A1] I’m fine, but I woke up late today.
- u: did you go to sleep late last night
- m: [A1] Yeah, I did. I shouldn’t have.
- u: what did you do up so late
- m: [A1] I just couldn’t sleep.
- u: i sometimes have trouble sleeping too
- m: [B1] Do you wake up in the middle of the night because of those dreams ?
- u: yeah, sometimes i wake up from nightmares
- m: [A2] I think you watch too many horror movies.
- u: i do enjoy horror movies but my dreams are not about them
- m: [B1] oh my goodness ! i like horror movies, too.
- u: what’s your favorite horror movie
- m: [B1] nightmare before christmas is my favorite.
- u: i haven’t seen that one
- m: [B1] You can’t help it but to scream.
- u: i’ll check it out
- m: [A1] Okay.
- u: do you have any other suggestions
- m: [A2] Try hiking sometimes.
- Specified level: A1
- Legacy model
- To meet the time performance of the scoring model we had to come back to the simpler solutions. We used a stacked ensemble of a bag-of-words model and a neural network model. The neural network uses a CNN with mean pooling and attention. This solution is fast and reliable. At the same time it provided us with surprisingly good performance.
- Data Engineering
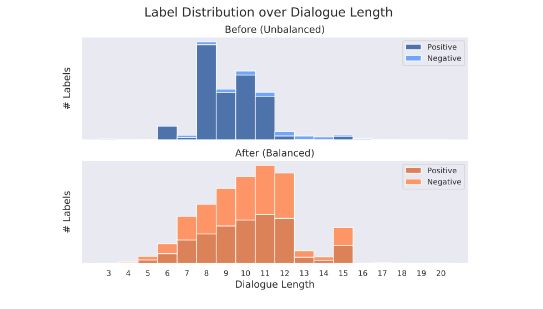
- The most important aspect of Machine learning model development is the data which is used for training. We keep collecting the highest quality open domain dialogue data. However, there is one caveat of the data from the point of view of classification task which occurs natuary with our data collection procedure – the overrepresentation of positive labels. There are a huge pallet of solutions available to counter this problem and we are still in search of the best one.
- The majority of the data we use to train our model is in the form of a sequence of “correct” sentences, such as “after sentence A comes sentence B.”
- If we train a model only using such positive labels, the resulting model will tend to give high scores to unseen sequences of utterances that are actually incorrect, meaning that it will give false positive results.
- To mitigate this problem, we approached it in two different ways:
- 1. Simply collect more negative labels
- Our Synthetic Tree data collection system can already gather such negative labels.
- However the labels are given only to utterances that already exist in our database.
- We wanted to experiment with generative models, and we needed feedback on the performance of the generative models. So we interfaced the Synthetic Tree task to collect feedback for the performance of the generative models. This produces negative labels that we can also use to train the scoring model.
- 2. Artificially create negative labels, by choosing a random (high chance of being wrong) utterance at the end of a dialogue sequence.
- While this method can produce a lot of negative examples, the generated negative samples will be so obviously wrong, the resulting model may have trouble distinguishing a correct response from a subtly wrong response.
- 1. Simply collect more negative labels
- Going back to BERT
- Previously our best model was based on BERT. It’s a bidirectional transformer pre-trained using a combination of masked language modeling objective and next sentence prediction on a large corpus. Then it can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks. However, it is hard to tame such complicated models and it is even harder to scale them. To efficiently use these models one has to spend a lot of computational resources to perform hyperparameter tuning and reproduce experiment results. To achieve higher computational efficiency we experimented with DiltillBERT, SqueezeBERT and MobileBERT – the pruned versions of the original BERT model.
- Hyperparameter Search
- Machine learning models are very sensitive to the choice of hyperparameters. We started with using gridsearch and then switched to more advanced hyperparameter optimization algorithms (optuna). The use of pruned models and increase of computational power dedicated to the task we can ensure the best performance.
- Fortissimo – a unified way to keep track of the perceived performance of the system
- So far we’ve relied on machine learning metrics like accuracy and F-score to determine the performance of the individual systems. However such metrics don’t always directly translate to “how good it seems” to the user.
- We implemented a subsystem in our data collection site that gathers feedback from our editors on the quality of the responses. This is tightly coupled with various hyperparameters in the overall pipeline, so we can make changes and quickly see how it affects the quality of responses, separate from the ones given by the training process, such as model accuracy.
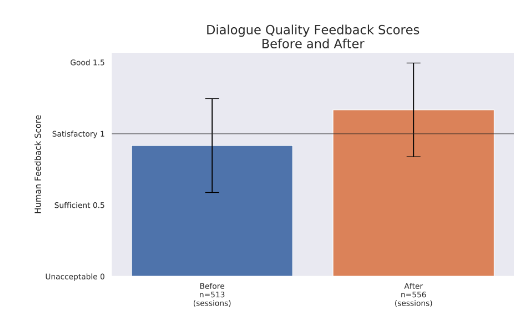
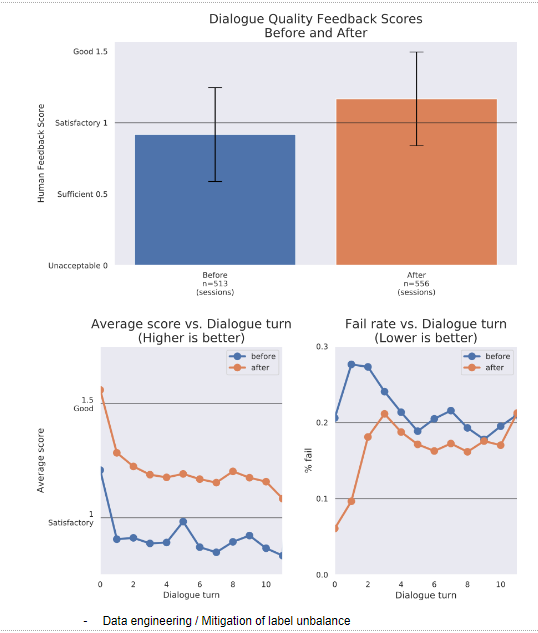
- Boxes in blue show the distribution of feedback scores from editors before the update was in effect.
- Boxes in orange show the distribution of feedback scores from editors after the update.
- We let the system collect the feedback data for about two weeks.
Musio Product page: https://themusio.com/
Muse V2 Videos: Part 1: https://youtu.be/60Gy5Z9cM3Q, Part 2 : https://youtu.be/lGzkiT-ZSOY, Part 3 : https://youtu.be/OtOoltqXqME
